
🔍 Want to look up an IP reputation score right now?
Enter any IP address into threatYeti and get a full reputation score, threat breakdown, and infrastructure context — no account required. Free, instant, no rate limit for manual lookups.
Every security product that touches network traffic needs to make a decision: is this IP address a threat, or isn’t it?
An IP reputation score is supposed to answer that question. But how the score is calculated, what it actually tells you, and how to translate it into a block or allow decision — that’s where most implementations fall apart. This post breaks down exactly what’s inside an IP reputation score, how to query one via API, and how to use it without generating a wave of false positives or missing active threats.
What Goes Into an IP Reputation Score
Not all reputation scores are created the same way, but most high-quality IP reputation systems evaluate a combination of the following signals:
Historical behavior. Has this IP been observed hosting malware, running phishing pages, or participating in spam campaigns? For how long, and how recently? A single incident two years ago carries less weight than repeated activity in the last 30 days.
Co-location signals. Who else is on this IP? Cloud hosting and bulletproof hosters routinely pack hundreds or thousands of domains onto a single IP address. If a large portion of those co-located domains are flagged as malicious, that’s a meaningful signal about the infrastructure — even if the specific domain you’re looking at is new and has no history of its own.
ASN and network reputation. Some autonomous systems are reliably clean. Others consistently appear in threat feeds. The network a host lives on contributes to its baseline risk. A freshly registered domain hosted on an ASN known for abuse is a different risk profile than the same domain hosted on a major cloud provider.
Blocklist appearances. Has this IP appeared on established blocklists? How many, and how recently? Blocklist hits alone don’t make a good reputation system — they lag too far behind — but they’re a useful corroborating signal.
Open ports and response behavior. What’s actually running on this IP? Open ports associated with known attack patterns, unusual server banners, or TLS certificates that don’t match the domain are all signals that a well-built reputation system factors in.
One important caveat: WHOIS data — registrar, registration date, registrant contact — exists at the domain level, not the IP level. If you want that context, you need to pivot from the IP to its associated domains (via same-IP relations) and run enrichment from there. IP-level network registration data (ASN, org, RIR records) tells you who owns the address block, not who registered the domain hosted on it.
What a High-Confidence IP Reputation Score Looks Like in Practice
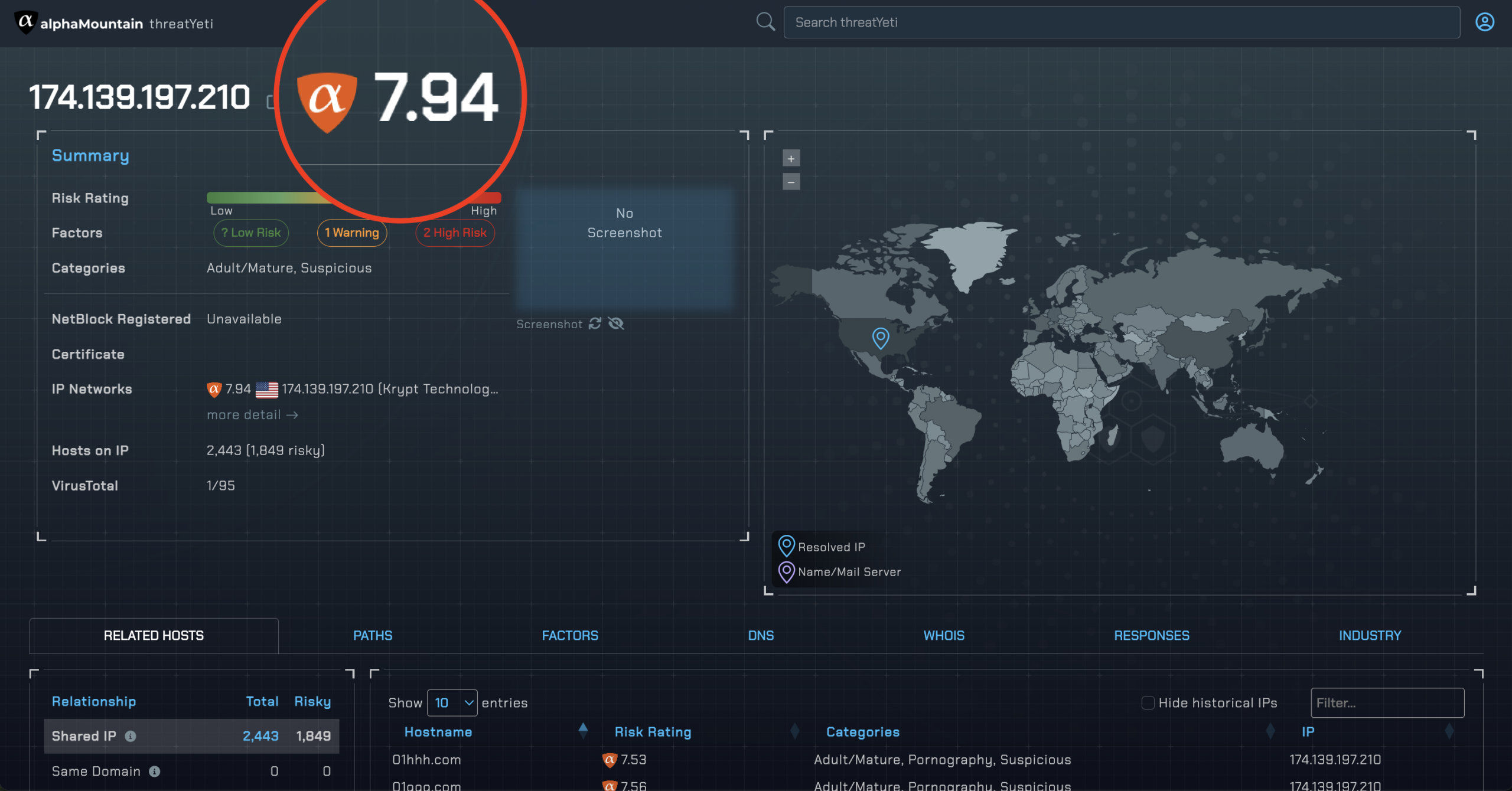
Here’s a real API response from aM Intelligence™ for a high-risk IP — 174.139.197.210, hosted on Krypt Technologies (AS35908):
{
"version": 1,
"hostname": "174.139.197.210",
"status": {
"geo": "Success",
"threat": "Success",
"category": "Success",
"relations_same_ip": "Success"
},
"summary": {
"low_risk": [],
"mid_risk": [],
"high_risk": [
"Host on Risky IP",
"High Risk Score"
]
},
"sections": {
"geo": {
"ipv4": [
{
"ip": "174.139.197.210",
"country": "United States",
"isoCode": "US",
"asn": {
"number": 35908,
"organization": "Krypt Technologies"
},
"rating": 7.94
}
],
"reverse": [
"customer.krypt.com"
]
},
"threat": {
"score": 7.94,
"scope": "domain",
"source": "αM-Labs"
},
"category": {
"categories": [3, 72],
"confidence": 0.970767,
"source": "αM-Labs"
},
"relations_same_ip": [
{
"hostname": "199nnq.sbs",
"ips": ["174.139.197.210"],
"first_seen": "2026-02-16T09:51:11.333Z",
"last_seen": "2026-05-26T08:37:04.580Z"
},
{
"hostname": "19tuoq.sbs",
"ips": ["174.139.197.210"],
"first_seen": "2026-02-16T11:40:08.067Z",
"last_seen": "2026-05-22T14:45:40.198Z"
},
{
"hostname": "89sl.com",
"ips": ["174.139.197.210"],
"first_seen": "2026-02-16T16:19:56.258Z",
"last_seen": "2026-03-18T23:14:01.277Z"
},
{
"hostname": "www.332wwq.sbs",
"ips": ["174.139.197.210"],
"first_seen": "2026-02-16T12:55:37.010Z",
"last_seen": "2026-05-19T20:13:12.566Z"
}
]
}
}
A few things worth noting in this response:
The score (7.94) lands in block territory. The summary object surfaces the human-readable drivers — “Host on Risky IP” and “High Risk Score” — which is what you’d surface in a SOC alert or an end-user block page explanation.
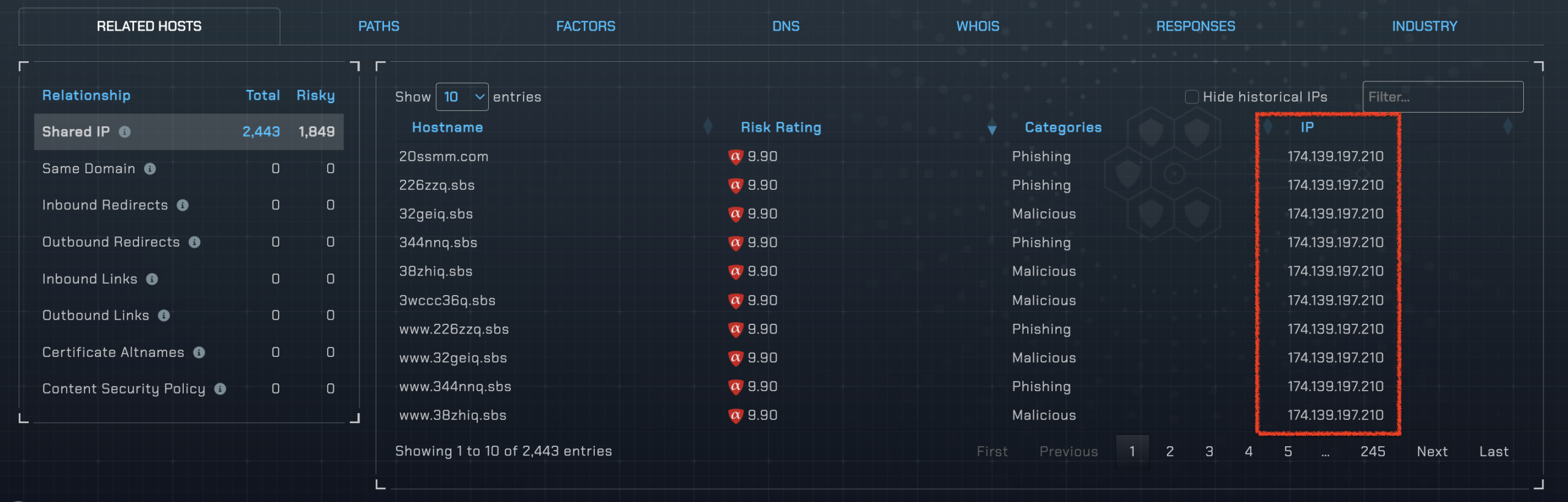
The co-located domains are a tell. The relations_same_ip array shows multiple domains all registered on the same day (2026-02-16), all using the .sbs TLD — one of the highest-risk TLDs on the internet — with names that follow an obvious randomized alphanumeric pattern: 199nnq.sbs, 19tuoq.sbs, 332wwq.sbs. This is a classic bulk-registration fingerprint. You don’t need to wait for each of those domains to accumulate their own threat history — the shared infrastructure pattern is the signal.
The category confidence is 97%. The category.confidence field (0.970767) tells you how certain the AI model is in its classification. High confidence scores on threat-related categories mean you can act on them with lower risk of a false positive.
To get registrar or WHOIS context, pivot to the domains. The IP-level response tells you the ASN org (Krypt Technologies) and geographic region, but registrar, registration age, and registrant data live at the domain level. From the relations_same_ip list, you can query any of those hostnames directly to pull full domain enrichment — including WHOIS, passive DNS history, and impersonation probability.
The Biggest Mistake: Treating IP Reputation as Binary
The most common implementation mistake is treating a reputation score as an on/off switch — below 5.0, allow; above 5.0, block. This produces two failure modes:
False positives at scale. Shared hosting means a legitimate small business site can sit on an IP with a mid-range reputation score. A hard cutoff at 5.0 will catch genuine threats but it’ll also block things you don’t want to block.
False negatives on new infrastructure. A freshly spun-up phishing IP may start with a score of 4.5 — not clean, not flagged. If your threshold is 5.0, it sails through. For the first several hours, new malicious infrastructure often looks borderline — this is intentional.
A better approach: Use the score as one input in a risk-tiered policy:
| Risk Rating | Recommended Action |
|---|---|
| 1.00 – 4.00 | Allow |
| 4.01 – 6.99 | Monitor / log with elevated priority |
| 7.00 – 7.99 | Soft block or step-up authentication |
| 8.00 – 10.00 | Block |
The exact thresholds depend on your risk tolerance and use case. A DNS filter serving enterprise networks will set a lower block threshold than a fraud detection system where false positives directly impact revenue. Decimal precision in your reputation API makes this tunable. A binary “clean / dirty” feed does not.
Freshness: The Variable Nobody Talks About
IP reputation scores are only as accurate as the data behind them — and data goes stale fast.
Phishing infrastructure is typically most damaging in the first hours after it goes live, before blocklists and feeds have caught it. A reputation API that updates daily leaves a predictable window that attackers actively exploit. New malicious IPs are spun up, used for a targeted campaign, and sometimes taken down — all within a 24-hour cycle.
The aM Intelligence™ API updates IP reputation scores hourly. For a DNS filter or firewall making real-time policy decisions, that gap between “daily” and “hourly” is the gap between catching a threat and missing it.
Using the Relations Data — Not Just the Score
The IP reputation score is the starting point, not the full picture. The relations_same_ip data is where the intelligence compounds.
In the example above, the co-hosted domains — all registered on the same day, all using randomized names on the .sbs TLD — tell a clear story about coordinated malicious infrastructure. A single new domain appearing on that IP tomorrow would inherit that context immediately, even before it’s accumulated any individual threat history.
This is the core argument for contextual enrichment over pure score-based decisions. A score without context is a number. A score with co-location data, passive DNS history, and the ability to pivot into related domains for deeper enrichment is a decision.
Getting Started with the IP Reputation API
The aM Intelligence™ API accepts any IP address (IPv4 or IPv6) and returns the full reputation dataset — score, threat summary, categories, relations, geo — and more — in a single call.
Key response fields:
sections.threat.score— the 1.00-10.00 decimal risk ratingsummary.high_risk/summary.mid_risk— human-readable breakdown of risk driverssections.category.categories— classification category IDs from alphaMountain’s 92-category taxonomysections.category.confidence— model confidence in the classification (0.0-1.0)sections.relations_same_ip— co-hosted domains with first/last seen timestampssections.geo.ipv4[].asn— ASN number and organization
Free API trial: [email protected]
For manual investigation — without writing a line of code — enter any IP into threatYeti to see the full intelligence picture in your browser.
Summary
An IP reputation score is a signal, not a verdict. The teams and products that get the most out of it treat the score as one input in a risk-tiered policy, pair it with co-location and infrastructure context, and know when to pivot into related domains for the full enrichment picture.
If your current IP reputation data updates once a day and returns a single number with no context, you’re taking kinetic action on incomplete signal.
Ready to see what your IP reputation data should look like? Start a free API trial or investigate any IP at threatYeti.com.